
| Data and Documentation | Chronology and News | Program Status | Publications | Related Data and Resources | Contact Points |
ICOADS Web information page (Wednesday, 11-May-2016 19:34:47 UTC):
Release 1c (1784-1949) Beta
1. Introduction
Preliminary ("beta") Release 1c (1784-1949) data are completed. This page
provides some background, plus comparison results against original COADS
Release 1 data for 1854-1949. After additional analysis of the beta data and
assessment of duplicate elimination (dupelim) performance, it is planned to
rerun Release 1c processing to produce final observational and statistical
products for this period, with LMRF availability planned by mid-February 2001.
2. Data source additions
Following is a brief discussion of the new input datasets. Note that report
counts are as input to dupelim, after initial quality controls and conversion
to LMR. As a result some counts reflect some changes from earlier (raw)
report estimates (e.g., the Maury Collection was previously estimated at 1.4M
reports).
a) Blend of the UK Main Marine Data Bank (MDB) with COADS for the period
1854-1949 (decks 201-255; 11.7M reports): Copies of TD-1100 decks in MDB
were deleted (9.6M reports during 1854-1949) prior to this stage.
b) Maury Collection (deck 701; 1784-1863; 1.3M reports): This deck provides
the only data for 1784-1803, and substantial new data additions after that.
c) Norwegian Logbook Collection (deck 702; 1867-89; 201K reports).
d) Japanese Kobe Collection data (deck 762; 1890-1932; 1M reports): These are
data more recently keyed by Japan (decks 118-119, which are among the COADS
COADS Release 1 data, were keyed in the 1960s).
e) US Merchant Marine 1912-46 Collection (decks 705-707; 3.5M reports): A few
data also included back to 1910.
f) Russian Makarov Collection (deck 731; 1804-1891; 3.5K reports): 27 ships
including the "Vitiaz" in two partially overlapping collections.
g) World Ocean Database 1998 (WOD98; deck 780; 405K reports), including sea
surface temperature estimates derived from the uppermost layers of ocean
profiles, and some surface meteorological fields (CTD and XBT archives
were outside of the Release 1c period).
h) Arctic drift stations (deck 734): For this period the deck includes two
Norwegian ships overwintering in the Arctic:
i) Data from the North Polar expedition of the "Fram" (1893-96, North
of 76N; 8K reports) were obtained from Volker Wagner at the Deutscher
Wetterdienst (German Weather Service), and with the assistance of the
US National Snow and Ice Data Center (NSIDC).
ii) NCDC-keyed data covering 1922-24 (7K reports) from the North Polar
expedition with the "Maud" (1918-25) were obtained also with the
assistance of NSIDC.
i) Russian AARI North Pole (NP) Station (manned drifting ice floe) data from
the Polar Science Center (deck 733; NP-1 for 1937-38; 1K reports).
j) Russian MARMET (deck 732; 268K reports starting about 1888) marine
meteorological archive (previously known as MORMET).
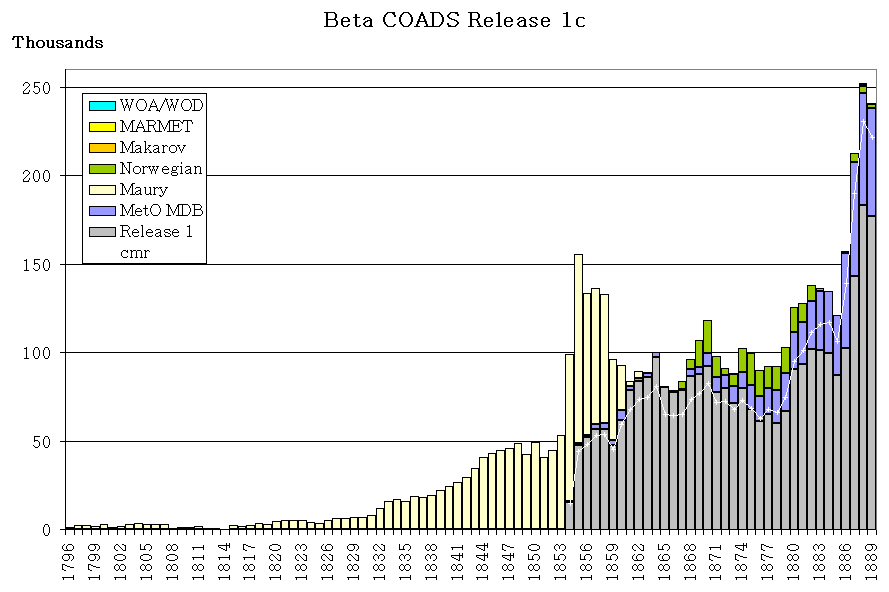
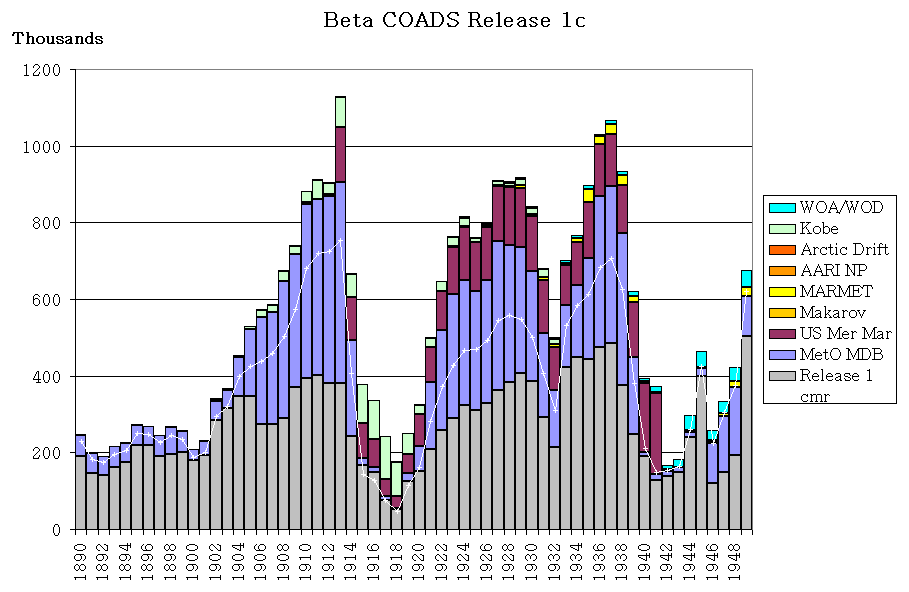
Figures 1-2 illustrate new data additions made to the Release 1c period, in
comparison to existing Release 1 data (note that in some cases significant
reductions in report counts occur as a result of dupelim processing):
Figure 1: Dupelim output: 1796-1889 deck composition. Decks originally
used for Release 1, and also output for Release 1c, are aggregated under
the gray bar. Other bar colors are used for decks new to Release 1c.
The line shows the total dupelim output for Release 1, for comparison.
Figure 2: Dupelim output: 1890-1949 deck composition (otherwise as for
Fig. 1).
Notes:
i) The Release 1 dupelim output as shown in Figures 1-2 is based on counts
of Compressed Marine Reports (CMR), in which uncertain duplicates had
been removed. The beta output is based on LMR, but the counts were
reduced to account for most uncertain duplicates (see sec. 4c), plus
for landlocked reports. After adjustment the counts correspond exactly
to LMRF, but are only roughly comparable with CMR counts (for reasons
including retention in CMR of landlocked reports). (This approximate
relationship is not estimated to have a major impact on items ii-iii.)
ii) In many cases in Figure 2 (e.g., 1904-14), fewer reports from Release
1 decks were output in the beta (i.e., the line is above the tops of
the gray bars). We think this usually indicates that decks new to
Release 1c were selected instead. For example, some of the UK MDB
decks thereby replaced inferior or less complete copies of the data
that were originally included in Release 1.
iii) Conversely, in some cases (e.g., 1864) the line falls below the tops
of the gray bars. This means that more data from the Release 1 decks
were output in the beta than were output for Release 1. Sec. 4d
describes a duplicate elimination problem that we believe accounts
for this unexpected inflation (undetected duplicates).
3. Data problems
Examples follow, but it should be noted that many of the early collections
may be lacking in metadata or contain data problems not listed here (e.g.,
unadjusted pressures or magnetic wind directions):
a) Maury Collection: Most of the wind directions may be magnetic. We are still
looking into the feasibility of adjusting directions based on historical
fields of magnetic declination (NOAA/NGDC may be able to help with this).
In the absence of any metadata as to instrument type, barometers were all
assumed to be mercurial and adjusted for gravity, and also adjusted for
temperature if attached thermometer data were available (a flag was set
indicating whether one or both corrections were made). Detailed information
about the conversion of this Collection to LMR format, including corrections
made to temperatures, is available here:
icoads.noaa.gov/maury.html
Further examination of the temperatures and other data is underway at NCDC
(e.g., to explore whether Reaumur temperatures are embedded among those
now labeled Celsius).
b) Dutch (deck 193) sea level pressures: Pressures were recovered from the
supplemental attachment and adjusted for gravity. This accounts partially
for large increases in pressure data coverage (see sec. 4) particularly
in the 19th century. However, an estimated 3% of the data may have been
taken with aneroid barometers, and thus should not have been adjusted for
gravity (the problem appears unresolvable at this time, due to a lack
of metadata).
c) Dupelim problems: Additional tuning of the dupelim procedure still appears
needed to ensure that more unique data are retained, such as a "pass though"
of some decks that were subject to comparison with other decks during the
beta run. Also, some rules (e.g., exact time/space match) that were
developed for Release 1a processing appear to have been too stringent for
these earlier data (in the beta version of LMRF we retained exact time/
space uncertain duplicates, i.e., DS=6, to alleviate some problems).
d) Undetected duplicates: An additional dupelim problem in the beta run
was that duplicates went undetected for some combinations of German,
Dutch, HSST, and MDB decks, because of no allowance for small sea level
pressure differences. For example, this occurred in Dutch (deck 193)
versus HSST (decks 155-156) matches as a side-effect from recovery of
SLP in deck 193. Based on sample matches, the recovered SLP values
tended to match HSST decks to about 0.1 hPa. But this altered dupelim
performance, since SLP was expected to match exactly. We are addressing
this in the rerun by extending to deck 193 (and similarly to other known
deck combinations impacted by SLP differences) an existing deck 192-HSST
allowance (#4), that considered pressures to match if they agreed to
whole hPa.
4. Comparisons of near-global (62N-62S) time-series using "concurrent" 2°
boxes
Comparisons (see Appendix for plot details) are presented for two periods:
1854-99, and 1900-49. Dataset1 is COADS Release 1, and dataset2 is the
COADS Release 1c beta (output from dupelim) for the overlapping periods
(Release 1c extends back to 1784 with some new data). Year-month summaries
for 2° boxes were calculated from the beta data for 1854-1949, such that
the data were trimmed at 4.5 sigma and all platform types were included (e.g.,
some oceanographic data become available in the late 19th century).
Figure 3a: 1854-99: Sea surface temperature.
Figure 3b: 1854-99: Air temperature.
Figure 3c: 1854-99: Scalar wind.
Figure 3d: 1854-99: Sea level pressure.
Figure 3e: 1854-99: Total cloudiness.
Figure 4a: 1900-49: Sea surface temperature.
Figure 4b: 1900-49: Air temperature.
Figure 4c: 1900-49: Scalar wind.
Figure 4d: 1900-49: Sea level pressure.
Figure 4e: 1900-49: Total cloudiness.
Notes on Figures 3a-3e and 4a-4e:
i) Pushing the print button will print all the figures in a set (e.g.,
3a-3e), since they are all colocated on the same page.
===============================================================================
Appendix: Explanation of each 4-panel plot page comparing two datasets
a) Departures
For each variable, 2° latitude/longitude boxes in the region 62°N-62°S were
included in the comparison only if they possessed data "concurrently" (i.e.,
for a given year-month) from both dataset1 (left) and dataset2 (right). This
ensures a comparable grid within each monthly time step, but not a frozen grid
through time. Departures were calculated for each year-month-2° box, and each
dataset, of monthly means with respect to a basic 1950-79 COADS Release 1
long-term monthly mean (LTM). (Note that the data used to construct the LTM
were also means, not medians.) Each concurrent 2° box departure value was
cosine-weighted,* from which the area weighted average was computed. The top
panel contains two separate curves of the area-weighted average departures
(black = dataset1; green = dataset2). It should be emphasized that this type
of comparison does not reveal anything about data patterns in either dataset
outside of the region defined by the set of concurrent boxes for each
year-month.
b) Differences
The green curve is the area-weighted average, as calculated for plot a), of the
difference between 2° monthly means for dataset1 minus dataset2 (i.e., both
datasets must possess a monthly mean for a given 2° box to be included in the
difference). This set of boxes may be larger than the set of concurrent boxes
used for the departures.** The black curve, which corresponds almost exactly
(and is thus invisible on many of the plots), is the non-area-weighted average
of the differences.
c) 2° boxes
The black curve shows the number of concurrent*** 2° boxes; the green curve
shows that number plus the number of non-concurrent 2° boxes containing only
data from dataset2 (the number of non-concurrent 2° boxes in dataset1, if any,
is not shown). The green curve also includes any 2° boxes containing data in
dataset2 that were not available in the 1950-79 LTM; such boxes were also not
included in plot a).
d) Numbers of observations
Using only the set of concurrent**** boxes for each year-month, the green curve
shows the number of observations for dataset2, and the black curve shows the
corresponding number of observations for dataset1. Curves are not shown for
any additional observations falling in 2° boxes represented in either dataset
outside of the set of concurrent boxes.
----------
* The method used by GrADS employs the "delta of the sin of the latitudes at
the edges of the grid box," rather than the central latitude of the box.
** The set of boxes used for the differences (plot b) may be a superset of the
set of concurrent boxes used for the departures (plot a), because we did
not require that the LTM exist for a given box-month for it to be included
in the differences. Moreover, the set of "concurrent" boxes used for the
counts of boxes and observations (plots c and d) is that defined by the
differences, not the departures. The problem arises because the trimming
limits (owing to interpolation and extrapolation), as well as the Release
1c data, may be more extensive (covering more boxes) than the 1950-79
LTM. Note that if one were comparing two untrimmed datasets, which might
therefore both contain many box-months not represented in the 1950-79 LTM,
the set of boxes used for the differences might be considerably different
than that used for the departures.
*** The set of concurrent boxes is that defined by the differences, which may
be a superset of that defined by the departures (see footnote under b).
**** The set of concurrent boxes is that defined by the differences, which may
be a superset of that defined by the departures (see footnote under b).
{kind=link}
{kind=link}
[Delayed-mode (ICOADS.DM) Archive][Release 1c (1784-1949)]
U.S. National Oceanic and Atmospheric Administration hosts the icoads website privacy disclaimer
Document maintained by icoads@noaa.gov
Updated: May 11, 2016 19:34:47 UTC
http://icoads.noaa.gov/r1c_beta.html